
Introduzione a Cassandra
Da poche settimane l'API Cassandra di Azure ComosDB č globalmente disponibile al pubblico. Lo scopo di quest'articolo č di introdurre brevemente Cassandra (abbreviato spesso come C*), un database quasi onnipresente in discorsi riguardo il trattamento di dati su larga scala.
Quest'articolo, il mio primo per voi, sara' forse molto meno pratico rispetto al solito. Mentre interfacciarsi con Cassandra č abbastanza semplice, le barriere concettuali comprese nella sua adozione possono facilmente provocare “lamenti e stridor di denti” se non affrontati. Non sarŕ possibile coprire tutte le basi, ma l'idea č di approfondire sufficientemente alcune delle principali questioni piu' teoriche, magari aprendo cosě la via per un discorso molto piů pratico in futuri articoli.
Introduzione
Lo sviluppo di Cassandra inizia nel 2008 in Facebook. Nel 2009, Cassandra entra sotto l'ala dell'incubatore Apache e, nel 2010, diventa un progetto di primo livello. (maggiori informazioni disponibili su qui e qui).
Apache Cassandra č sviluppato come progetto open source. Il supporto commerciale viene offerto da un buon numero di aziende di cui la piů conosciuta č probabilmente DataStax, azienda che appartiene a un gran numero dei principali sviluppatori del progetto open source.
Cassandra č concepito come database distribuito. Apple (75000 nodes, 10PB), che impiega anche un gran numero di contributori al progetto open source, e Netflix (2500 nodes, 420TB) mantengono due delle installazioni di produzione di Cassandra piu' grandi al mondo.
Strumenti
Per iniziare a sperimentare con Cassandra, come con qualsiasi base dati, servono:
- accesso a un'istanza del database;
- dati con dei modelli di esempio;
- un modo di collegarsi, ovvero un driver con adeguata documentazione, per l'ambiente di sviluppo preferito.
Ottenere accesso a un'istanza Cassandra č molto semplice. Partendo dall'immagine docker disponibile qui, č possibile creare un semplice cluster di piů istanze in locale per lo sviluppo a costo zero. Sono anche numerose le opzioni SaaS, come Azure CosmosDB Cassandra, che permettono di configurare un cluster Cassandra in pochi passi (documentazione disponibile qui.
Per quanto concerne la necessitŕ di dati e modelli di esempio, esiste il progetto open source Cassandra Dataset Manager. Anche se lo sviluppo di questo progetto sembra stagnante, offre comunque la possibilitŕ di accedere a dei dataset preconfezionati per Cassandra estremamente utili a scopo didattico.
Per quanto riguarda i driver esistono numerose alternative per gli ambienti di sviluppo piů comuni di cui si puň trovare una lista a questo indirizzo. Per .NET sono stati sviluppati e sono in continua evoluzione i seguenti driver:
- Cassandra Sharp;
- Datastax. Da notare che questo driver non č per DataStax Enterprise, la versione estesa commerciale di Cassandra offerta da DataStax, bensě per Apache Cassandra, la versione open source;
- FsCassy. Progetto per F# molto promettente.
Il Cassandra Query Language (noto piů semplicemente come CQL) ha una sintassi semplice che a prima vista somiglia molto a SQL. Ricordiamoci perň che non č SQL e che Cassandra non č un database relazionale. Per chiarire meglio il concetto basta pensare che non esiste il concetto di JOIN. Visto che lo scopo di quest'articolo č teorico, non approfondiamo CQL. Sarŕ invece lo scopo di un futuro articolo piů particolareggiato. Anche nei vostri esperimenti personali, ricordatevi: it looks like SQL, it sounds like SQL, but it's NoSQL.
Cassandra č un sistema distribuito
Lo sviluppo di Cassandra in Facebook fu motivato dalla necessitŕ di rendere piů efficiente la ricerca di messaggi privati tra utenti. In un post del 2008, di cui riportaimo uno stralcio, uno dei principali sviluppatori di Cassandra svela le motivazioni tecniche del progetto.
The amount of data to be stored, the rate of growth of the data and the requirement to serve it within strict SLAs made it very apparent that a new storage solution was absolutely essential. The solution needed to scale incrementally and in a cost effective fashion.
Nei discorsi legati a Cassandra viene spesso nominato il teorema CAP e quest'articolo non č un'eccezione. Il teorema CAP, largamente, indica che una base dati distribuita, cioč un sistema di storage con dati localizzati su piů nodi connessi tramite una rete, non garantisce piů di due delle seguenti proprietŕ [7,8]:
- Consistency - la consistenza dei dati restituiti. Questo significa che č garantito che una volta registrata una modifica, un cliente riceve sempre la copia piů aggiornata di un dato, o un errore;
- Availability - il sistema č sempre disponibile e risponde ad ogni richiesta con un dato (non necessariamente aggiornato), o un errore;
- Partition Tolerance - il sistema č resiliente a errori di rete che possono isolare uno o piů nodi, e impedire la comunicazione tra alcuni nodi.
Anche se citato spesso, il teorema non č immediatamente praticabile e in molti casi viene malinterpretato. Č un interessante risultato teorico che rispecchia contesti semplificati ma che, secondo l'autore, ha portato molto lavoro fruttifero nel campo dei sistemi distribuiti.
Prima di tutto gli errori di rete sono un fenomeno che qualsiasi sistema di storage distribuito deve prevedere. Le reti falliscono, c'est la vie, quindi rimane la possibilitŕ' di offrire al cliente o l'accessibilitŕ del dato, o la consistenza.
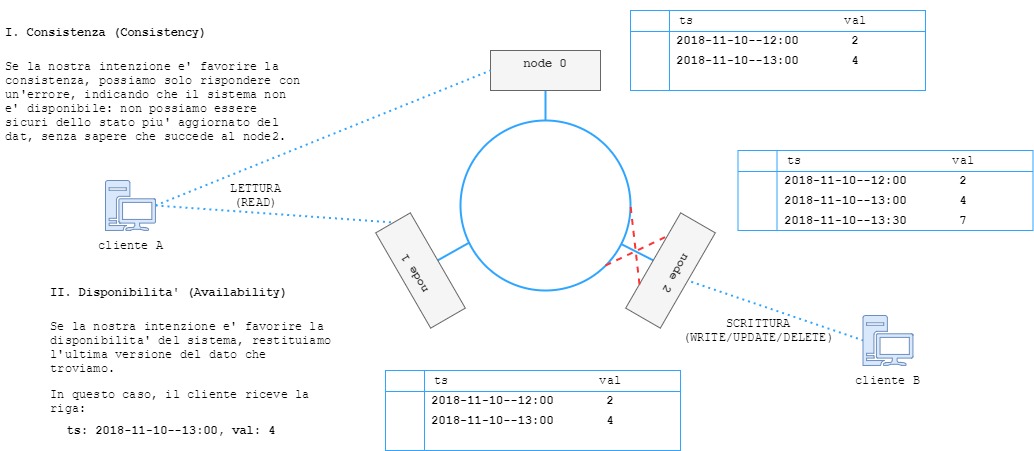
Immaginiamo che una riga debba essere aggiunta in un sistema di base dati distribuito su tre nodi come in figura. I dati sono replicati su ogni nodo. Supponiamo che per intervento divino il nodo 2 non sia raggiungibile dagli altri nodi del sistema. Il cliente B č connesso al nodo 2 ed era in corso un'operazione di scrittura. Il nodo 2 conosce il valore piů aggiornato, ma non puň comunicare questa informazione alle altre repliche. Le altre repliche possono comunque essere raggiunte dai client. Un sistema che favorisce la consistenza potrebbe restituire un errore al client A, non sapendo che fine abbia fatto l'operazione sul nodo 2, ed essendo impossibile garantire una risposta con il dato piů aggiornato. Un client C collegato in lettura sul nodo 2, riceverebbe la stessa risposta.
Un cluster Cassandra č masterless, ogni nodo č uguale a livello decisionale. Cassandra gestisce la replica (configurabile) dei dati all'interno del cluster, ed č costruita con l'obiettivo di avere un'alta disponbilitŕ dei dati. Al client A in figura, Cassandra restituirebbe comunque l'ultimo dato disponibile, sul nodo che elabora la richiesta, anche se non aggiornato.
Per default, Cassandra restituisce sempre ciň che esiste sulla replica che elabora la richiesta di un client. Per esempio, se vari client chiedono lo stesso dato ripetutamente dopo l’esecuzione di un'operazione di aggiornamento, anche nell'assenza di problemi di comunicazione inter-nodo, potrebbero ricevere risposte diverse in base alla replica dove viene elaborata la richiesta di lettura. Col passare del tempo, tutte le repliche si aggiorneranno, e il dato sarŕ consistente in tutto il cluster. Questo comportamento si chiama eventual consistency. Č possibile configurare la consistenza in Cassandra, specificando il numero di repliche che devono concordare sul valore di un dato prima che questo venga restituito. E' comunque un argomento delicato, visto che cambiare il livello di consistenza puň influire enormemente sull'efficienza (e quindi anche sui vantaggi) di Cassandra.
Per fare un esempio pratico, in un cluster Cassandra come quello in figura dove ogni nodo č isolato dagli altri, ma č comunque capace di ricevere richieste da client, un client potrebbe ricevere o la riga delle ore 13:00, l'ultima aggiornata sui nodi 0 e 1, o la riga delle ore 13:30 sul nodo 2. Č possibile configurare il livello di consistenza di Cassandra, ma sarŕ un argomento per futuri articoli.
Questo significa che Cassandra non č necessariamente la prima scelta in un contesto dove abbiamo bisogno di consistenza assoluta e abbiamo volumi di dati che ci permettono di un RDBMS in maniera economica. Cassandra serve quando il volume e la frequenza di aggiornamento dei dati sono alti. Immaginiamoci un cluster che riceve centinaia di migliaia di richieste di scrittura da sistemi IoT ogni secondo, o che debba tracciare dati di navigazione per ogni utente che visita un sito molto trafficato. Questi sono scenari per cui le esigenze di larga scala rendono l'assoluta consistenza in lettura proibitivamente costoso o estremamente inefficiente.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.



 7")