
Utilizzare le stored procedure con Entity Framework
Introduzione
Grazie a LINQ to Entities, scrivere query in Entity Framework č estremamente semplice. L'espressivitŕ di questo linguaggio permette di ottenere grafi complessi di oggetti semplicemente interrogando il dominio senza conoscere nulla di SQL e della reale struttura del database sottostante. Inoltre, la capacitŕ di generare il codice SQL per la persistenza degli oggetti elimina la necessitŕ di scrivere codice SQL del tutto.
Se sembra troppo bello per essere vero č perché in effetti non sempre lo č. In molte situazioni il codice generato dalle query č prolisso e sproporzionato rispetto al compito da svolgere. Inoltre, in fase di persistenza degli oggetti spesso si devono eseguire delle operazioni aggiuntive tipo memorizzare dei dati in un log o aggiornare tabelle che non sono gestite con Entity Framework. In aggiunta, in molti ambienti i DBA preferiscono avere pieno controllo sui comandi che vengono lanciati sul database. Tutte queste condizioni rendono l'uso delle stored procedure un must. In questo articolo vedremo come Entity Framework interagisce con queste funzioni.
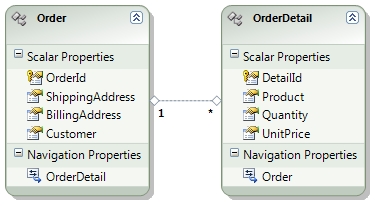
Prima di cominciare ad analizzare come sfruttare le stored procedure diamo un'occhiata al modello per capire i vari scenari. Il primo caso č un classico modello ordine-dettagli.
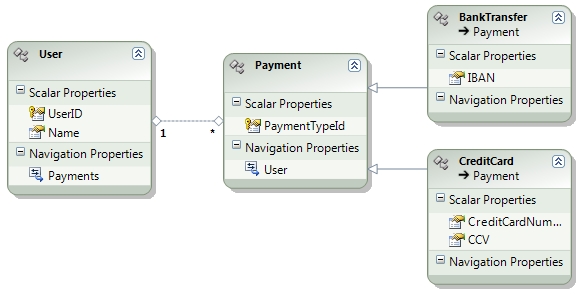
Il secondo modello prevede l'ereditarietŕ mappata con un modello Table-per-hierarchy. Le classi Payment, BankTransfer e CreditCard sono mappate con la tabella PaymentType. Ogni utente, puň avere piů sistemi di pagamento.
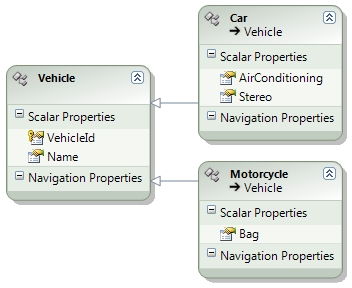
L'ultimo modello prevede il mapping col modello Table-per-type. Vehicle č mappata con la tabella Vehicle, Car con la tabella Car e Motorcycle con la tabella Motorcycle.
Ognuno di questi scenari ha le proprie peculiaritŕ e deve essere trattato separatamente. Cominciamo con il parlare dell'utilizzo delle stored procedure che recuperano i dati dal database.
Stored procedure per recuperare dati
Esistono due modi per farsi restituire dati da una stored procedure: tramite uno o piů resultset e tramite parametri di output. Utilizzando Entity Framework, si possono sfruttare entrambi i metodi ma in modalitŕ diverse. Ad esempio, se si utilizzano piů resultset, č impossibile trasformare i resultset in entitŕ in maniera nativa ma bisogna ricorrere al codice, cosa invece possibile quando si torna un solo resultset. Partiamo quindi con l'analizzare il caso in cui ci sia un solo resultset.
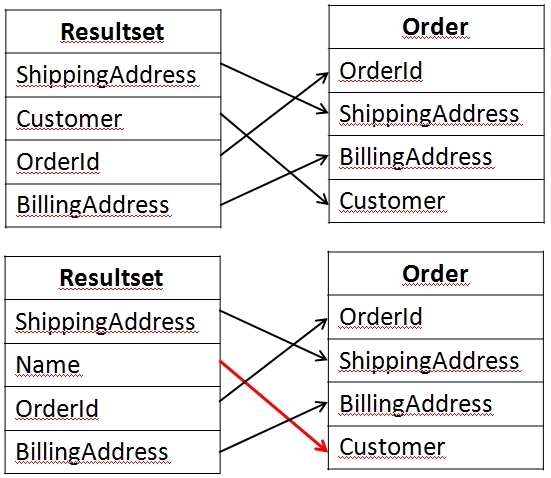
La prima cosa da sapere quando si lavora con le stored procedure č come avviene il mapping tra i campi del resultset restituito e le proprietŕ dell'oggetto che deve essere creato. Visto che siamo nel mondo del mapping, ci si aspetterebbe che questo processo sia deciso in questo modo. In realtŕ, il processo č basato sul match tra i nomi delle colonne del resultset e le proprietŕ semplici dell'oggetto da creare (per proprietŕ semplici si intendono quelle che non puntano ad altre classi nel dominio). Inoltre, le colonne del resultset devono mappare tutte le proprietŕ dell'oggetto creato altrimenti si genera un'eccezione a run time. La seguente immagine mostra chiaramente come avviene il processo. Nel primo caso il mapping avviene regolarmente. Nel secondo caso la colonna Name non puň essere mappata sulla proprietŕ customer e si genera l'eccezione.
Ovviamente, nel caso il resultset restituisca piů colonne di quante necessarie, queste vengono semplicemente ignorate ed il mapping avviene senza problemi. Vediamo ora come importare la stored procedure nel nostro modello ed utilizzarne il risultato.
Commenti

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.



